Structure
The data sources of BRENDA comprise three main domains: Text mining data, manual annotation and external databases and ontologies.
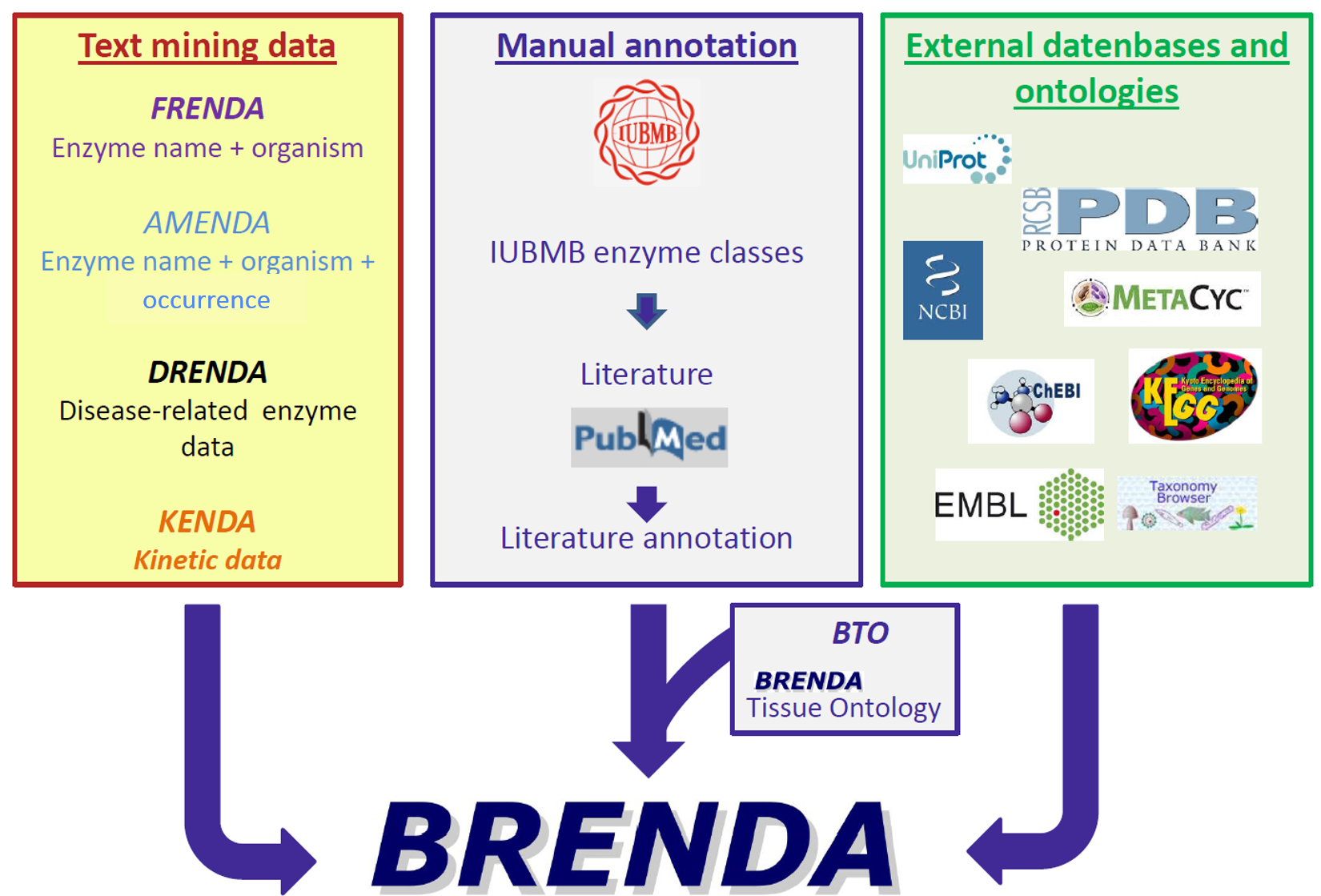 Organization of BRENDA® contents
Organization of BRENDA® contentsThe supplementary sources FRENDA (enzyme name & organism), AMENDA (enzyme name & organism & occurence), DRENDA (disease-related enzyme data) and KENDA (kinetic data) complement the BRENDA core by text mining data.
The manually annotated core is based on IUBMB enzyme classes and literature from PubMed. Additionally, the BRENDA tissue ontology (BTO) is linked to the manual annotation.