TRANSFAC® KNOWLEDGE GRAPH
Grounded biological data
for AI drug discovery
TRANSFAC Knowledge Graph integrates 38+ years of manually curated transcriptional regulation, causal signaling, and disease biology delivered as MySQL tables licensable for AI training.
FOR AI DRUG DISCOVERY TEAMS
TRANSFAC
Transcription factors & binding sites
TRANSPATH
Causal signaling reactions
HumanPSD
Diseases, biomarkers, drugs & clinical trials
The grounding problem
Public data sets are built for exploration, not for grounding production AI
01
Layer · Big-data alone
Large language model–style training works because text is abundant and homogeneous. Biology is neither. Drug discovery datasets are small relative to the dimensionality of the systems they describe, and the raw omics are noisy.
Models trained on raw omics from scratch learn statistical correlations and miss causation, which is why they look strong on benchmarks and fail on a new disease subtype, cell type, or patient cohort.
Omics datasets alone give a model of the vocabulary of biology without the grammar. Models trained on them can speak fluently and still be wrong.
02
Layer · Public knowledge bases
Adding public motif and pathway databases helps. They are real curated knowledge. But they are fragmented, simplified, and missing the cell type and tissue-specific detail that drug discovery actually depends on.
It’s the difference between learning a language from a tourist phrasebook and learning it from a proper grammar.
The stakes
In drug discovery the cost of the wrong or incomplete grammar is measured in years and in capital, not in test set accuracy.
Robust AI for drug discovery doesn’t come just from more data. It comes from comprehensive, manually curated molecular biology — the kind that took 38 years to build.
Three curated layers. One licensed database.
A licensed biological knowledge graph delivered as MySQL tables, integrating three curated layers built and maintained by the geneXplain team over 38 years. Every entry links to its primary literature. Every reaction has a direction. Every annotation carries an evidence class. Updates ship twice a year.
Transcription factors with their experimentally verified binding sites and the most comprehensive library of DNA motifs — the foundation of regulatory genomics for nearly four decades.
Causal, directional signal transduction reactions across the proteome including modified forms and protein complexes. Not correlation networks — curated reactions with direction, cellular context, and source.
Diseases, clinical trials, the largest collection of biomarkers and drug targets with mechanistic annotations and evidence classes — connecting molecular biology to clinical context.
Cross-references resolve to Ensembl, UniProt, PubMed, Reactome, and Human Protein Atlas.
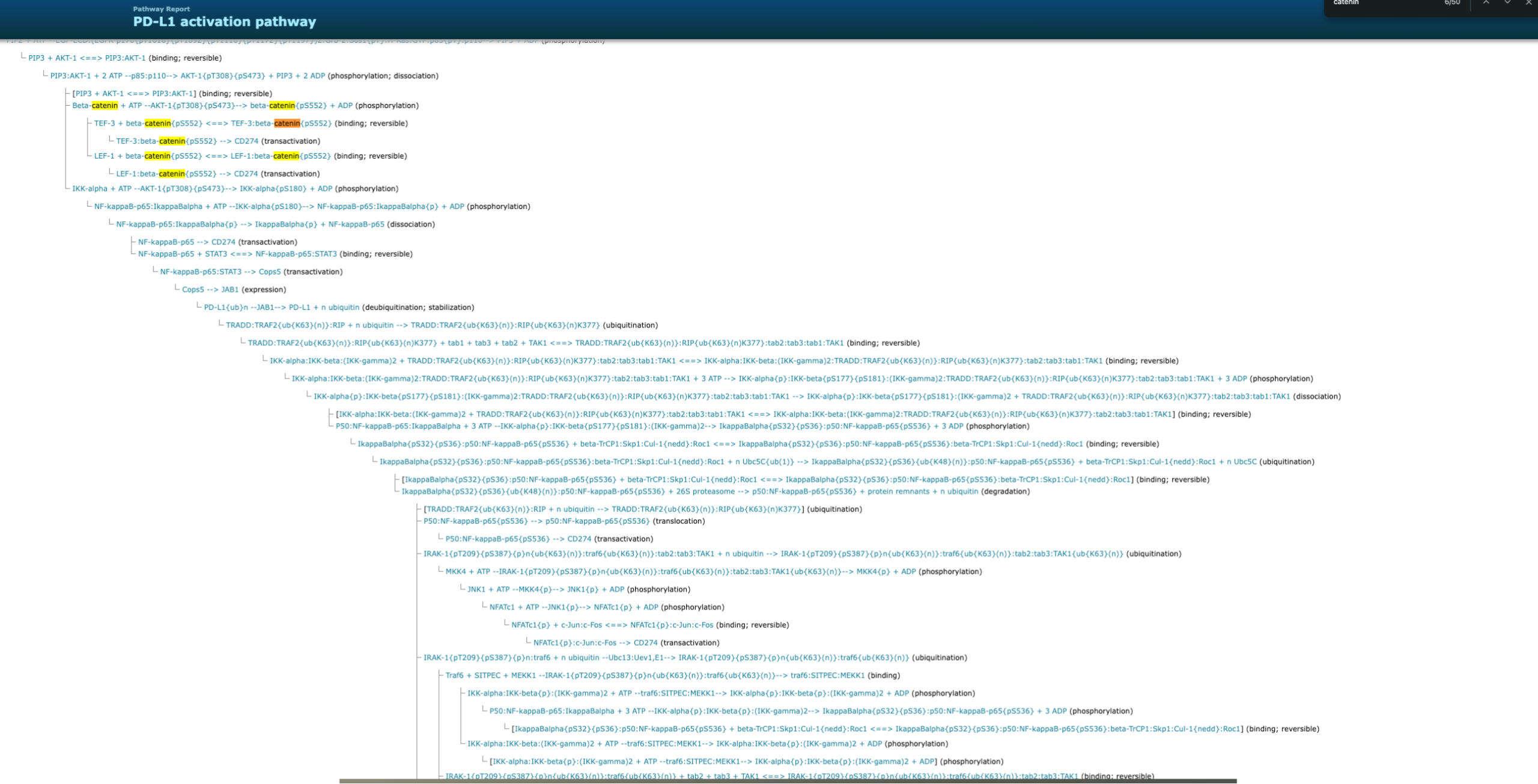
PD-L1: one molecule, three layers of knowledge.
A single immunotherapy target seen through TRANSFAC®, TRANSPATH®, and HumanPSD™ — regulatory grammar, causal signaling, and clinical context, integrated on one molecule.
TRANSFAC®
Transcription factors & binding sites
50+ predicted TFBS in CD274 promoter
Experimentally validated: STAT3, IRF-1
Cell-type context (A549 + IFN-γ)
TRANSPATH®
Causal signaling reactions
Dozens of curated upstream reactions
6 TF complexes transactivate CD274
PTMs mapped (phospho, ubiq, glyc)
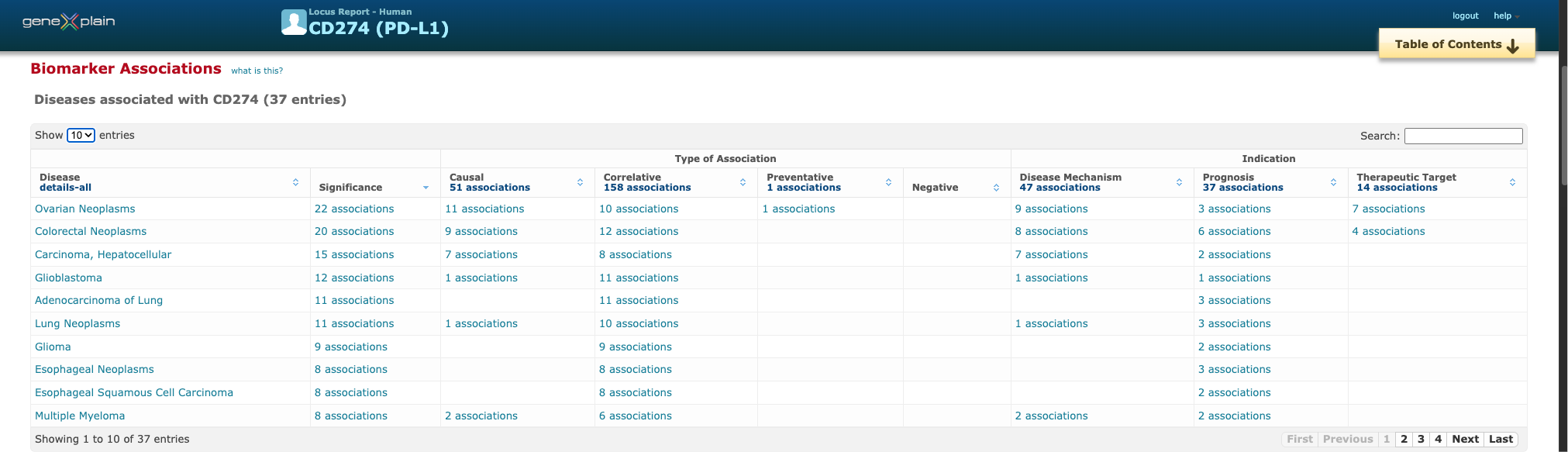
HumanPSD™
Diseases, biomarkers, drugs, clinical trials
37 diseases associated
51 causal · 158 correlative
47 mechanism · 37 prognosis · 14 target
All three layers integrated as the full PD-L1 activation network.
Six numbers that frame what’s inside
12,469
DNA motifs (PWMs) across all taxa
118,987
Experimentally verified binding sites
>1.2M
Signal transduction and metabolic reactions
1,631
Pathways
>1.4M
Drug -Disease -Clinical Trial links
802,036
Biomarker annotations
Public databases are not bad. They are insufficient for grounded AI
Public databases often give you fragmented sequence motif collections, mixed genes or protein features, statistical correlations, and aggregated network edges.
TRANSFAC Knowledge Graph gives you curated entries traceable to the experiments that produced them, reactions with a direction and cellular context, signaling pathways reconstructed from primary literature, and disease predictive and prognostic biomarkers and drug targets.
TRANSFAC Knowledge Graph provides
✓ High-quality manually curated database (>1,000 person-years of curation)
✓ Causal, directional reactions (not correlation)
✓ Primary-literature provenance on every entry
✓ Mechanistic disease biomarker classification
✓ Signal transduction pathways
✓ Curated updates twice a year
✓ Licensable for AI training
| Data requirement | TRANSFAC® Knowledge Graph | Public motif databases | Public pathway / network databases |
|---|---|---|---|
|
Integration across biological layers |
Unified schema connecting DNA motifs → TFs → regulatory modules → signaling pathways → disease biology → drugs |
Typically focused on regulatory layer only |
Typically focused on pathway/network layer only |
|
Curated TF binding motif collection |
>11,000 expert-curated PWMs derived from experimentally validated TFBS with manually optimized alignments ensuring high biological fidelity |
High-quality open motif collections with broad coverage; typically fewer profiles and less harmonization across experiments |
Not applicable |
|
Experimentally verified TF binding sites |
Extensive curated TFBS dataset with links to TFs, genes, species, experimental context, and literature evidence |
Often focused on motif models or ChIP-derived regions; experimental site-level annotation is more limited or heterogeneous |
Not applicable |
|
Composite regulatory elements (TFBS combinations) |
Unique strength
Curated and computationally derived combinations of TF binding sites (composite elements) capturing cooperative and combinatorial regulation — critical for real gene control logic |
Typically represent individual motifs; limited or no systematic modeling of TFBS combinations |
Not applicable |
|
Context-specific motif collections |
Ready-to-use tissue-, cell-type-, and disease-specific motif and TFBS collections reflecting biological context |
Context annotations exist but are not typically delivered as structured, ready-to-use regulatory layers |
Not applicable |
|
Genome-wide TFBS predictions |
Genome-wide TF binding maps across ~1,000 TFs, >300 cell types, and >50 tissues using PWMs and MEALR models |
Genome-wide predictions available but usually less context-aware and less focused on combinatorial regulation |
Not applicable |
|
Enhancers and silencers (context-specific regulatory elements) |
Unique strength
Expert-predicted genome-wide enhancers and silencers specific to tissues, cell types, diseases, and phenotypes, based on regulatory grammar and TF combinations |
Enhancer datasets exist (often experimental) but are typically not integrated with TF combinatorial logic or mechanistic regulatory modeling |
Not applicable |
|
Causal signaling reactions |
Large-scale collection of curated causal, directional signaling reactions suitable for mechanistic modeling |
Not applicable |
Strong pathway resources exist, but may include mixed evidence types (causal and associative) |
|
Mechanistic molecular detail |
Explicit representation of genes, proteins, isoforms, post-translationally modified forms, and protein complexes, enabling true mechanistic resolution |
Not applicable |
Pathway resources provide structured reactions but often simplify molecular states or aggregate entities |
|
Protein complexes and modified forms |
Detailed modeling of complexes and molecular states within signaling and regulatory processes |
Not applicable |
Present in curated pathways but depth and consistency vary |
|
Protein Genome Map (protein-centric genome annotation) |
New layer
Mapping proteins, their isoforms, modifications, and functional states back onto genomic regulatory regions, bridging genome and proteome in one framework |
Not available |
Not available |
|
Disease-specific pathways |
Expert-reconstructed disease pathways derived from curated biomarkers and causal signaling networks |
Not applicable |
Disease pathways exist but are often generalized or not reconstructed via causal graph approaches |
|
Disease biomarkers |
Structured biomarker knowledge classified by causality, mechanism, prognosis, and drug relevance |
Not applicable |
Disease associations present but not organized as a dedicated mechanistic biomarker layer |
|
Disease similarity maps |
Disease similarity networks based on shared biomarker profiles with expert-weighted evidence types |
Not applicable |
Disease relationships exist but usually not based on structured biomarker similarity modeling |
|
Literature traceability |
Each entry linked to primary literature with clear evidence annotation |
References provided but depth varies |
Curated resources provide references; large-scale networks may include predicted associations |
|
Data consistency and curation depth |
>38 years of continuous expert curation with consistent schema and harmonized biological representation |
Valuable open resources but variable consistency and depth |
Strong curated resources exist alongside aggregated datasets with mixed evidence types |
|
Best use case |
Mechanistic modeling, AI training, causal inference, and regulatory design |
Motif discovery, benchmarking, exploratory analysis |
Pathway enrichment and general network analysis |
|
Honest limitation |
Commercial licensed dataset optimized for depth, consistency, and mechanistic modeling |
Open and accessible; widely used for benchmarking |
Broad and accessible; may require integration and filtering for mechanistic use |
IN PRODUCTION
A leading AI drug discovery company licensed the full database in 2025 for foundation model training.
The company licensed TRANSFAC® Knowledge Graph to ground their foundation model in regulatory biology that survives downstream validation.
The data underlying the database has been used in peer-reviewed work on master regulator identification in colorectal cancer, systems medicine identification of repurposable therapeutics in IBD, and integrated transcription regulation analysis.
Selected references: Myer et al., Gastro Hep Adv (2022); Kel et al., BMC Bioinformatics (2019); Lloyd et al., Disease Models & Mechanisms (2020); Kolmykov et al., Nucleic Acids Research (2020).
Where TRANSFAC® Knowledge Graph changes your results
What makes the difference is not the number of motifs or pathways, but the ability to represent how they work together: as composite regulatory elements, context-specific enhancers, and mechanistically resolved molecular states.
01
Foundation model grounding
Models trained on raw omics or aggregated public data tend to learn correlations that do not generalize. Grounding your model in curated regulatory, signaling, and disease knowledge adds causal structure, biological constraints, and traceability to primary literature.
02
Mechanism-based target discovery
Expression-based approaches identify associations. Causal upstream modeling connects disease phenotypes to transcriptional master regulators through signaling pathways, enabling identification of actionable targets rather than correlated markers.
03
Multi-layer integration
Instead of stitching together separate motif, pathway, and disease resources, all layers are already connected in a single schema. Regulators, composite elements, signaling reactions, biomarkers, and diseases are linked consistently, enabling coherent mechanistic interpretation across relevant omics layers.
04
Synthetic regulatory module design
Regulatory design requires more than individual motifs. Using experimentally anchored binding sites, composite regulatory elements, and context-specific enhancer logic enables the design of promoters, enhancers, and regulatory circuits that reflect real biological control mechanisms.
Everything that ships with a license.
MySQL database containing TRANSFAC®, TRANSPATH®, and HumanPSD™ tables, including core entity tables and the cross-reference linking tables that connect them.
Experimental evidence annotations on regulatory entries, binding sites, and reactions.
Cross-references to Ensembl, UniProt, PubMed, Reactome, and Human Protein Atlas.
DOCUMENTATION
Schema documentation and data dictionary, field-level, in PDF.
Loader scripts for standard MySQL deployment.
LIFECYCLE
Contract-defined SLA for technical support, including database schema guidance, data ingestion assistance, and update integration.
Half a year updates with changelog and migration notes.
Delivery: within 10 business days of access being granted.
Selected worked examples and case study reports
Where integrated knowledge from TRANSFAC®, TRANSPATH®, and HumanPSD™ was applied to reveal the disease molecular mechanisms:
Full datasets and detailed outputs of these example applications are available during evaluation to illustrate how multi-layer biological knowledge can be used to ground and validate AI models in real-world scenarios.
What you license and what you don’t.
TRANSFAC®, TRANSPATH®, and HumanPSD™ MySQL tables; cross-references to Ensembl, UniProt, PubMed, Reactome, and Human Protein Atlas; experimental evidence annotations.
Some assets that customers sometimes assume are bundled with TRANSFAC are separate licensed products: derived position-weight matrices (PWMs), HMM models, Combinatorial modeling based on sparse logistic regression (MEALR) and technical tables required by the geneXplain GUI software.
Two license models. Scoped options on request.
Frequently asked questions
Bring your specific question. We’ll tell you whether the database fits.
The database has been developed and curated for 38+ years by the team that originated TRANSFAC®. Bring a target class, a disease area, or an evaluation requirement — we’ll help you to assess how the data can support your use case.

{kind=link}
{kind=link}
{kind=link}